Monorepo
任何一项技术的产生都是为了解决一些之前存在但没有解决的问题,所以要想学懂 monorepo,先要知道它解决了什么问题
Multirepos
Multirepos 是最自然的仓库管理方式,各个项目之间互相隔离,互不依赖
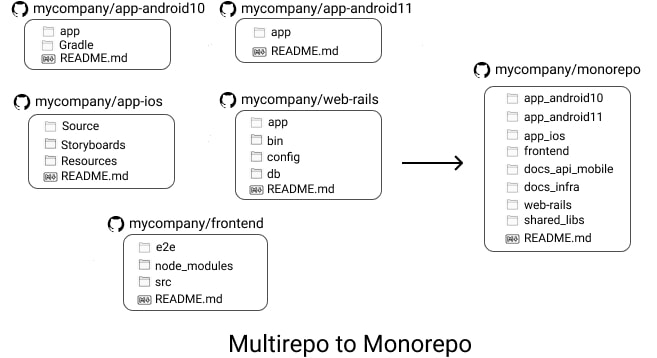
在开源的世界里,这种仓库管理方式似乎看起来十分自然,当然,不相关的仓库之间自然不需要通过 monorepo 进行管理
但,如果你正在开发一堆相互依赖的项目,这种项目管理方式的问题也逐渐暴露出来
项目基建
一个前端项目的诞生过程中,很多配置大同小异,比如lint,prettier,CI/CD等配置项,由于项目创建时间不同,参与人员不同,可能造成项目间代码规则、交付流程、格式化规则的差异,尽管这些内容可以通过自己封装脚手架来解决,但脚手架的通用性、成本、重构成本等依然成问题。
重复依赖
在传统的仓库管理方式中,每个仓库都会维护自己的package.json,当两个仓库同时依赖一个仓库的不同版本时,下游仓库打包时会重复打包依赖仓库的多个版本,变相地增加了 bundle 的体积,另外,在依赖链中,对包的语义化控制不能穿透到其子包,也就是包 a@patch 的改动可能意味着其子依赖包 b@major 级别的 Break Change。
多人协同
当公司内很多人维护同一个项目时,每个人精力有限,一个仓库的更新不一定能及时周知到其下游服务,可能几天后下游服务更新依赖才暴露上游依赖的 break change 导致线上事故
通过 CI/CD,我们可以比较容易地实现子集构建,但似乎很难实现增量构建,因为我们很难完整地收集到所有依赖当前仓库的项目。假设有若干个app依赖lib1依赖lib2依赖lib3,当 lib3 频繁变动时上线流程就会变得繁琐且危险
当我们需要调试一个库时,可能会在本地创建一堆 npm link,通过符号链接的方式引用本地依赖,而当本地项目足够多时,这种依赖方式将变得难以管理
通过 monorepo,我们可以轻易规避上述问题
monorepo 工具选择
截至 2022.11.04,monorepo 主流工具在 NPM 下载量 走势如下(仅做参考):
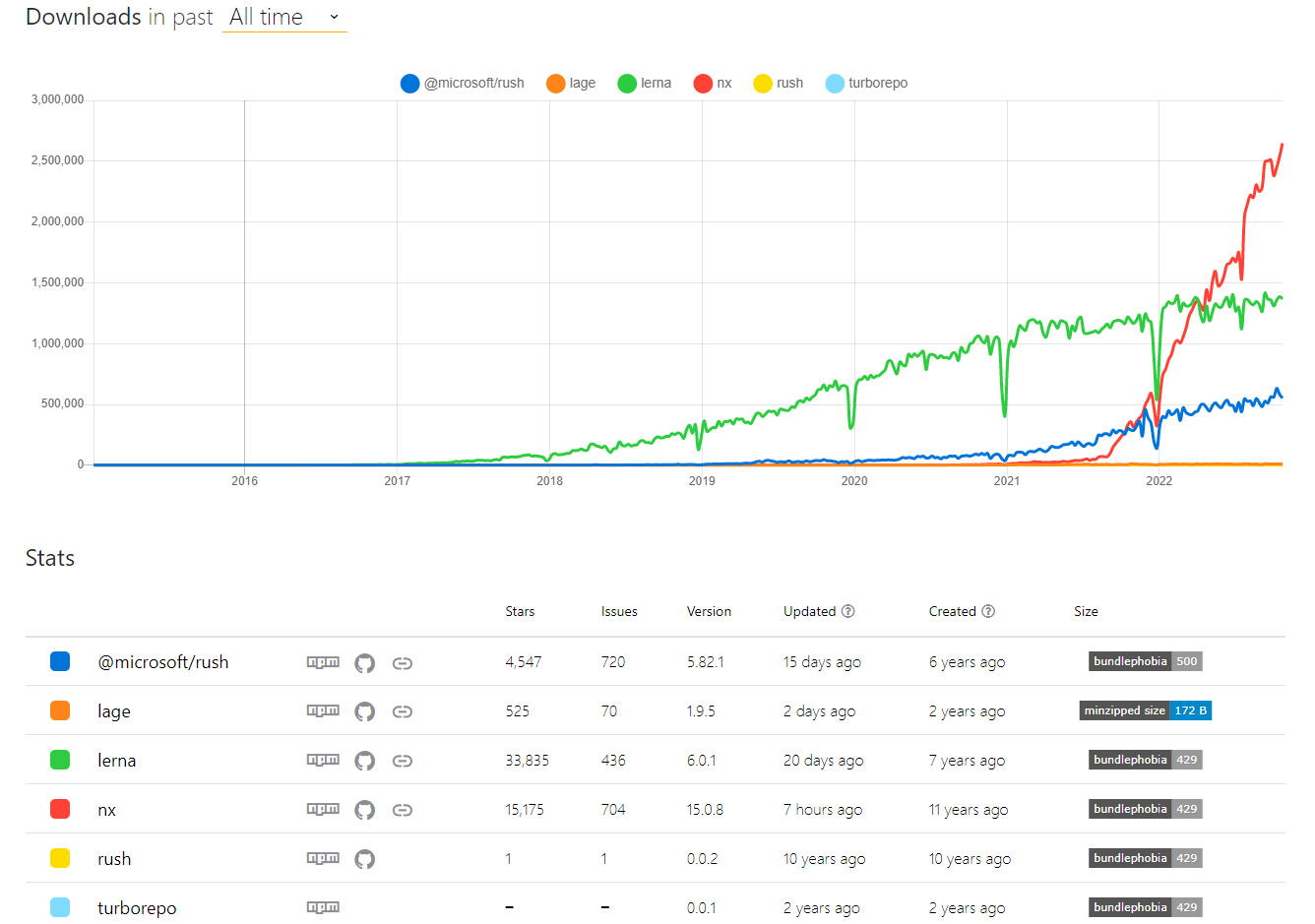
目前最主流的 monorepo 管理工具是nx lerna 和 @microsoft/rush
在mini-vue项目中,我将尝试使用turborepo进行 monorepo 的管理
TurboRepo 核心概念
以下内容部分来自于Turborepo 官方文档
本文仅摘取其中重点,加之本人的理解,若想了解更多,请前往查看官方文档
工作区(workspace)
一个monorepo项目至少包含一个工作区,一个工作区中可能包含一个或多个项目,例如:

- 某个monorepo项目中包含
apps和packages两个workspace apps下包含web和docs两个项目,packages下包含shared一个项目
任务(task)
我们任何一个前端项目,都会在package.json中定义一些诸如build,dev,test之类的脚本,在 turborepo 中,我们称之为任务(task),每一项任务都包含特定的输入输出,例如:
- 一项
build任务会将源码文件作为输入,bundle 文件和stderr/stdout作为日志输出 - 一项
lint或test任务会将源码文件作为输入,stderr/stdout作为日志输出
缓存机制
当我们首次开始执行一项任务时会发生什么呢:

- Turborepo 会把该项任务的输入转化为哈希(例如图中的 78awdk123)
- 检查本地文件系统缓存中以该哈希值命名的文件夹(例如./node_modules/.cache/turbo/78awdk123)。
- 如果 Turborepo 没有为计算的哈希找到任何匹配的文件夹,Turborepo 将执行任务。
- 任务结束后,Turborepo 将所有输出(包括文件和日志)保存到该哈希下的缓存中。
命中缓存
假设用户在不更改任何输入的情况下再次运行任务:

- 哈希将是相同的,因为输入没有改变(例如 78awdk123)
- Turborepo 将在其缓存中找到以该哈希值命名的文件夹(例如./node_modules/.cache/turbo/78awdk123)
- Turborepo 不会运行任务,而是重播输出之前保存的日志打印到 stdout 文件系统中并将保存的输出文件恢复到它们各自的位置。
从缓存中恢复文件和日志几乎是即时发生的。这可以将构建时间从几分钟或几小时缩短到几秒或几毫秒。尽管具体结果会因代码库依赖关系图的形状和粒度而异,但大多数团队发现,使用 Turborepo 的缓存,他们可以将每月的总体构建时间缩短约 40-85%。
配置缓存的输入和输出
turborepo 默认会将一个项目下.gitignore排除的文件之外的所有文件作为输入,并输出到./node_modules/.cache/turbo目录下,我们可以通过 配置turbo.json的方式 改变这种默认的行为,同时,我们也可以通过命令行或配置的方式禁用缓存
根据环境变量命中缓存
某些工具会在构建时注入环境变量,此时尽管由于环境变量的变更导致代码行为发生改变,因为输入的文件并没有变更,可能导致 turborepo 错误地命中缓存。在生产环境中,这种情况是十分致命的
我们可以通过 配置 ,使环境变量也参与到 turborepo 生成哈希的输入中来
eslint-config-turbo
使用eslint-config-turbo插件,会当你在代码中提及一个未在turbo.json中声明的环境变量时产生一个报错
远程缓存
turborepo 为团队协作的场景提供了远程缓存的能力,团队中不同机器可以通过 vercel 共享 远程缓存
多任务处理
turbo官方文档建议,使用你喜欢的包管理器管理依赖,使用turbo执行任务
大多数工具并未针对速度进行优化
yarn workspaces run lint
yarn workspaces run test
yarn workspaces run build

Turborepo 可以多任务处理
turbo run lint test build
